作者:夏天

11月27日晚间,细心的打工人发现,滴滴APP登陆不了,系统发生故障,服务无法正常使用。此次崩溃事件原因也引发诸多猜测——滴滴官微29日发布声明称,各项服务已经恢复,初步确定,这起事故的起因是底层系统软件发生故障,滴滴一夜损失近4亿。
无独有偶,阿里在11月也遭遇宕机,多款App同时出现异常。
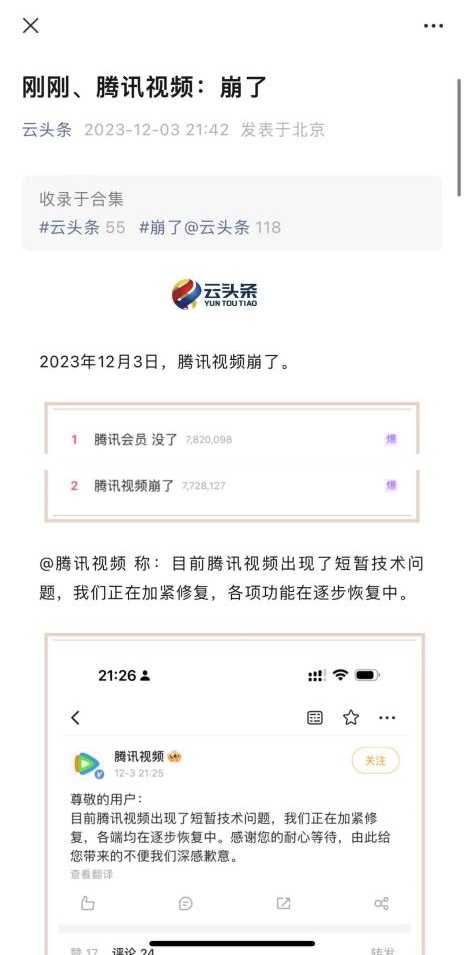
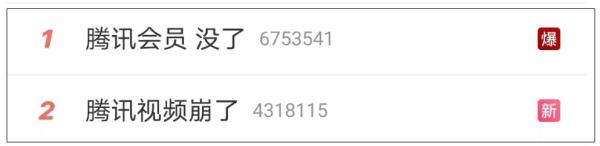
12月3日,腾讯视频也发生了崩溃问题,部分网友反应,自己在腾讯视频充值的会员显示不存在了,想观看会员频道影片也无法观看。

多次宕机引起了业内人士的广泛关注,对于互联网云企业而言,稳定性的问题仍然是亟待解决的难题。
腾讯云、阿里云的崩溃不禁让人思考,它们在软硬件方面是否足够安全?是否存在技术能力及冗余不足的问题?尤其在当下百模大战的背景下,大模型成为互联网巨头竞相下注的风口。从技术硬实力上看,它们真的准备好了吗?

据不完全统计,国内迄今已有130多个AI大模型问世,已发布79个10亿参数规模以上的大模型,涉及通用、垂直等不同类型,涵盖ToB和ToC各种场景。国外除了Chat-GPT,马斯克最近也推出首款大模型产品——Grok。它们自诞生之日起就雄心勃勃,想要在AIGC时代闯出一片新天地,但算力的紧缺与环境的复杂远超其想象。
算力作为智能时代的核心驱动力,直接决定着大模型的迭代与创新速度,算力的稀缺性已成为制约大模型发展的瓶颈所在。
但在算力维度,我们却饱受掣肘。今年10月,美国商务部对英伟达运往40个国家的芯片提出额外许可要求,以避免转售给中国,生效日期也从11月16日提前至10月23日,国内阿里、字节、百度等大厂均受到牵连,英伟达在国内的50亿美元订单化为泡影。
而在这其中,互联网公司最为“受伤”。当移动互联网的人口红利逐渐远去后,百度、腾讯、阿里等互联网领域佼佼者本想借着大模型的春风直上青云,却迎来“釜底抽薪”的困境。
从需求端来看,大模型堪称算力的“吞金兽”——全球头部AI大模型训练算力需求每3~4个月翻一番,即平均每年增幅达到10倍,按照大模型当下的发展进程,整体算力需求可能增至原来的100倍以上。
嗅觉灵敏的腾讯早就囤下了5万块H100芯片,而这却治标不治本,随着芯片消耗殆尽,算力问题依然得不到解决。再来看看百度,百度则是率先迈出了国产化第一步,于今年8月份下订单,向华为订购AI芯片,作为英伟达A100芯片的替代品。除此之外,中贝通信、恒为科技等算力运营商也已经与华为达成相关合作。

与此同时,我们看到大量互联网厂商并非自建算力基础设施,而是通过向云服务厂商购买云AI算力,来降低获取大量算力的成本和门槛。在该领域,提供昇腾AI算力服务的华为云,同样给了广大互联网厂商新选择。据了解,很多大模型公司也开始与华为云展开洽谈与合作。华为确实正成为国内继英伟达之后的“第二选择”。

区别于其他云服务商,华为基于自身的“厚”积累,走出了一条特色之路。一方面,面向计算,华为以硬件交付为主、提供算力业务。另一方面,面向客户,华为云以软件交付为主、提供服务业务。

我们来盘一盘华为云在算力服务方面的“技能点”。首先,华为云在贵安、乌兰察布、芜湖打造了3大AI云算力中心,为企业提供澎湃昇腾AI算力,企业和开发者无需自建AI数据中心,即可直接使用业界主流的开源大模型,让企业不再需要高价抢购“电子黄金”——GPU,无惧GPU断供挑战。
此外,昇腾云服务构筑全栈AI,提供稳定可靠极致算力,加快让千行万业实现大模型普惠,构建AI时代最佳云底座。
然后,在盘古大模型方面,已支持盘古自然语言、视觉、多模态、科学计算、预测等大模型能力,目前,基于昇腾AI云服务和盘古大模型进行联合创新,围绕AI大模型技术攻关、创新应用等领域展开与多伙伴深度合作,打造千行万业的专属大模型。
未来,中国大模型产业需要抱团前行,似乎才有出路。在大模型时代,我们看到,华为给自己的定位是“黑土地”,即通过算力底座、AI平台、开发工具,支持大模型在智能化时代的“百花齐放”。这也在大模型这条充满挑战性的赛道上,给了很多互联网企业一丝确定性的光亮和远方。


